In this post we introduce Newton’s Method, and how it can be used to solve Logistic Regression. Logistic Regression introduces the concept of the Log-Likelihood of the Bernoulli distribution, and covers a neat transformation called the sigmoid function.
We also introduce The Hessian, a square matrix of second-order partial derivatives, and how it is used in conjunction with The Gradient to implement Newton’s Method.
Similiar to the initial post covering Linear Regression and The Gradient, we will explore Newton’s Method visually, mathematically, and programatically with Python to understand how our math concepts translate to implementing a practical solution to the problem of binary classification: Logistic Regression.
Suggested prior knowledge:
- Derivatives and the Chain Rule (Calculus)
- Partial Derivatives & The Gradient(Multivariate Calculus)
- Basic Vector Operations (Linear Algebra)
- Basic Understanding of NumPy
- Basic Understanding of Independent Probability
The Data
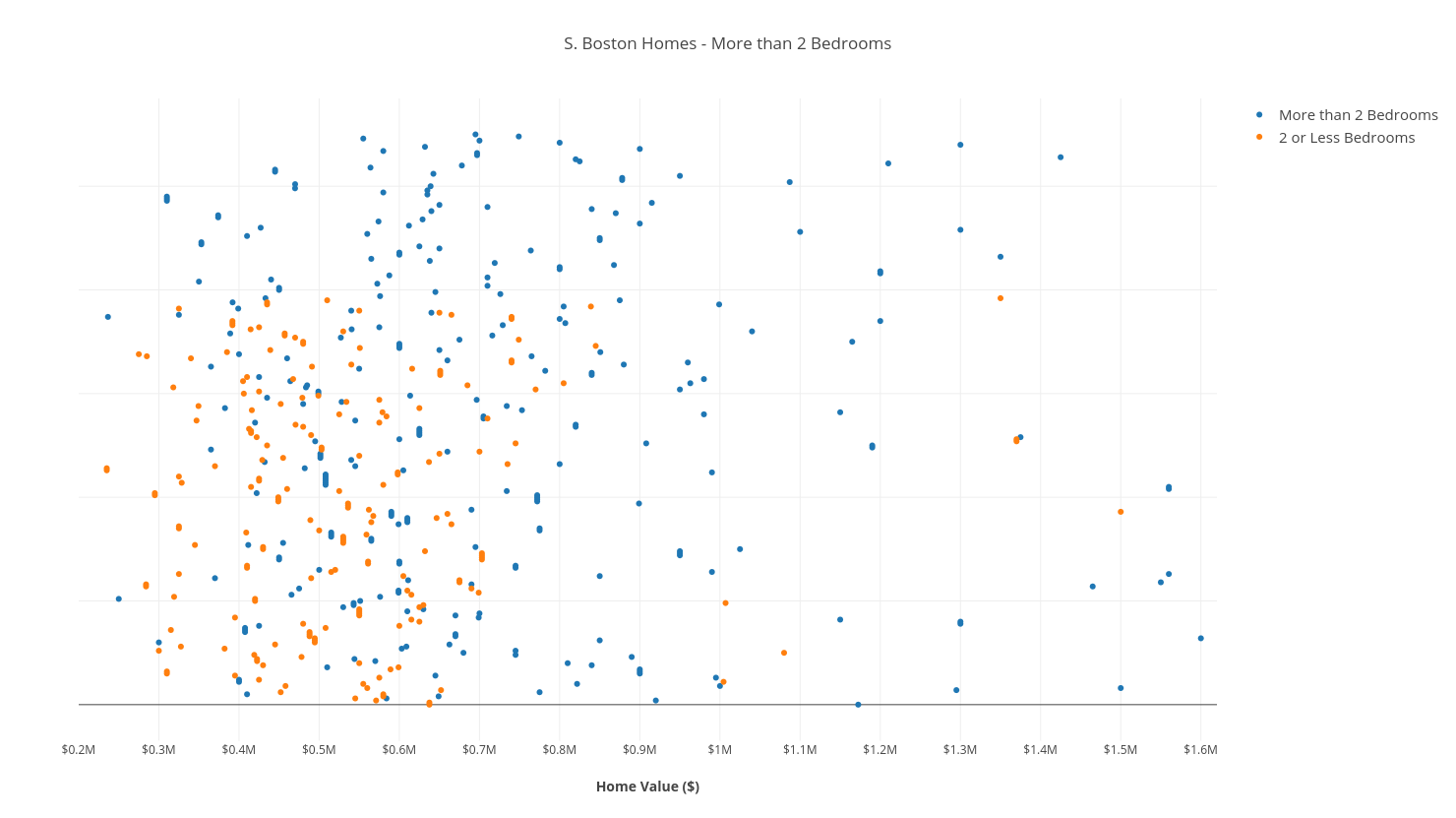
Our dataset is made up of South Boston real estate data, including the value of each home, and a (boolean) column indicating if that home has more than 2 bathrooms.
The Model
We will be learning a Logistic Regression model, that will act as a binary classifier predicting whether or not a home has more than 2 bathroom, given its value (in dollars).
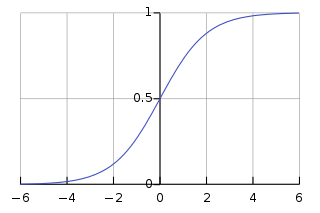
We still want to solve a linear combination of features & weights, but we need to transform this linear combination by wrapping it in a function that is smooth, and has its range defined as \([0, 1]\) (because we are trying to map our linear combination to a binary output of 0 or 1!)
The logistic function, or sigmoid function, accomplishes all of these things:
Note: We add \(\theta_{2}\) to the exponent as “the intercept” to provide more flexibility; we have 1 dimension of data, house_value, but we are solving a 2-dimensional model!
Similiar to the way we defined our sum of squares objective function for linear regression, we want to use our hypothesis function, \(h(x)\), and formulate our likelihood function to maximize and fit our weights. Here’s where things get mathy:
The Math: Defining a Likelihood Function
First we need to define a Probability Mass Function:
Note: The left-hand side of the first statement reads “The probability that y equals 1, given a feature-vector \(x\), and the hypothesis function’s weights \(\theta\).” Our hypothesis function (right-hand-side) calculates this probability.
These two statements can be condensed into one:
The table below shows how incorrect predictions by our hypothesis function (i.e. \(h(x)=.25, y=1\)) are penalized by generating low values. It also helps to understand how we condense the two statements into one.
| \(h(x)\) | \(y=0\) | \(y=1\) |
| .25 | .75 | .25 |
| .5 | .5 | .5 |
| .75 | .25 | .75 |
| .9 | .1 | .9 |
Naturally, we want to maximize the right-hand-side of the above statement, which happens to be our likelihood function.
I like to think of the likelihood function as “the likelihood that our model will correctly predict any given \(y\) value, given its corresponding feature vector \(\hat{x}\)”. It is, however, important to distinguish between probability and likelihood..
Now, we expand our likelihood function by applying it to every sample in our training data. We multiply each individual likelihood together to get the cumulative likelihood that our model is accurately predicting \(y\) values of our training data:
Seeing that we are multiplying “\(n\)” likelihoods together (all less than 1.0), where \(n\) is the number of training samples, we are going to get a product of magnitude \(10^{-n}\). This is bad news! Eventually, we will run out of precision, and Python will turn our very small floats to \(0\).
Our solution is to take the \(log\) of our likelihood function:
Note: Remember that \(log(xy) = log(x) + log(y)\), and that: \(log(x)^{n} = nlog(x)\).
This is called the log-likelihood of our hypothesis function.
Remember, our hypothesis function penalizes bad predictions by generating small values, so we want to maximize the log-likelihood. The curve of our log-likelihood is shown below:
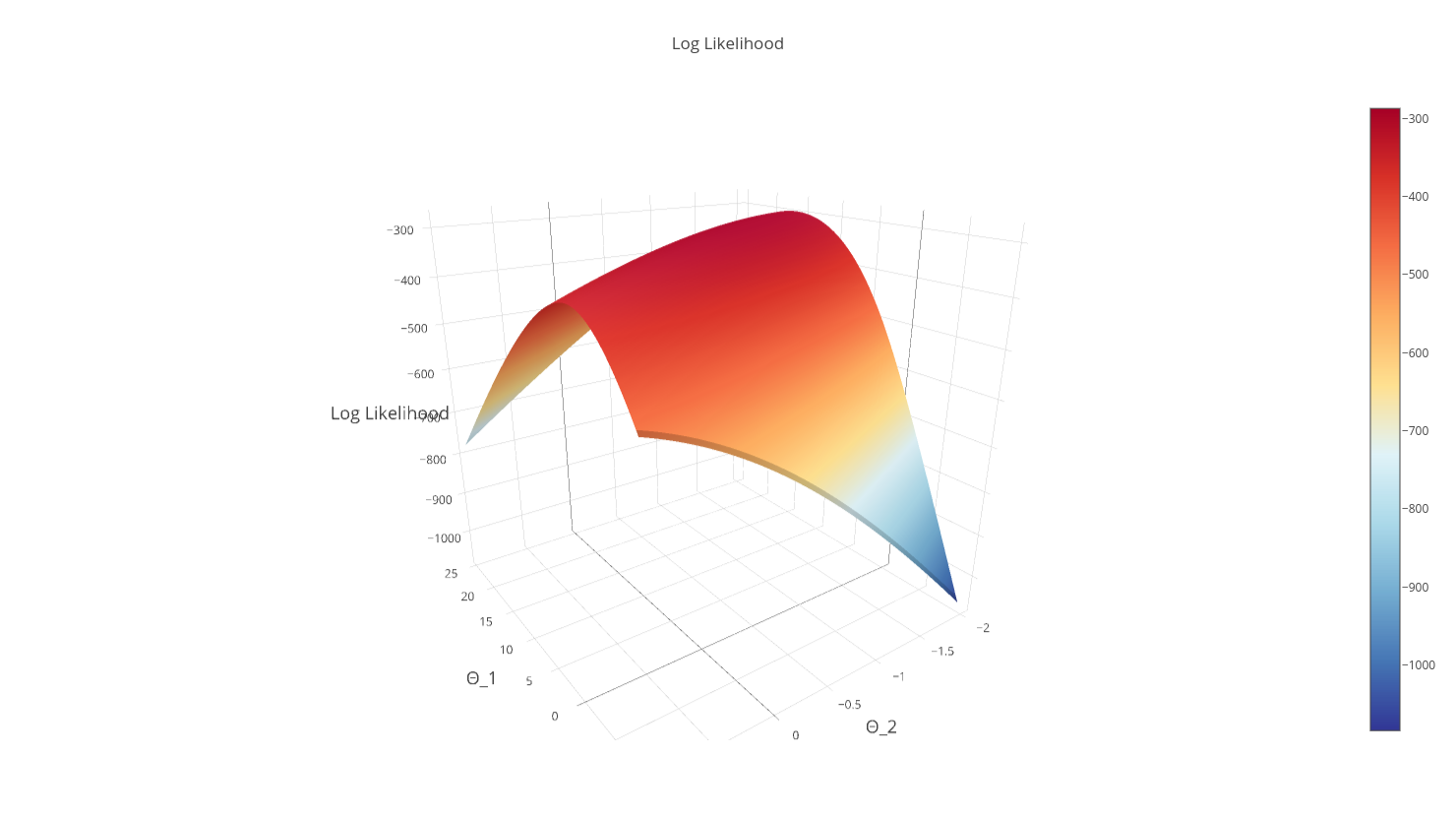
Note: By taking the log of our function to derive the log-likelihood, we guarantee (as an added bonus) that our objective function is strictly concave, meaning there is 1 global maximum.
The Math: Newton’s Method with One Variable
Before we maximize our log-likelihood, let’s introduce Newton’s Method.
Newton’s Method is an iterative equation solver: it is an algorithm to find the roots of a polynomial function. In the simple, one-variable case, Newton’s Method is implemented as follows:
- Find the tangent line to \(f(x)\) at point \((x_{n}, y_{n})\)
- \(y = f’(x_{n})(x - x_{n}) + f(x_{n})\)
- Find the x-intercept of the tangent line, \(x_{n+1}\)
- \(0 = f’(x_{n})(x_{n+1} - x_{n}) + f(x_{n})\)
- \(-f(x_{n}) = f’(x_{n})(x_{n+1} - x_{n})\)
- \(x_{n+1} = x_{n} - \frac{f(x_{n})}{f’(x_{n})}\)
- Find the \(y\) value at the x-intercept.
- \(y_{n+1} = f(x_{n+1})\)
- If \(y_{n+1} - y_{n} \approx 0\):
- return \(y_{n+1}\) because we’ve converged!
- Else update point \((x_{n}, y_{n})\), and iterate
- \(x = x_{n+1}, y = y_{n+1}\), goto (1).
The following .gif (from Wikipedia) helps to visualize this method:

If you understand the more-verbose algorithm above, you will see that this boils down to:
- Until \(x_{n} - x_{n+1} \approx 0 \):
- \(x_{n+1} = x_{n} - \frac{f(x_{n})}{f’(x_{n})}\)
Anyone who passed high school Calculus may be able to understand the above. But how do we generalize to the multivariate, “n-dimensional” case?
The Math: Newton’s Method in N-dimensions
Recall that in n-dimensions, we replace single-variable derivatives with a vector of partial derivatives called the gradient.
Review the gradient here if this concept is fuzzy to you.
Thus, our update rule, in its multivariate form, becomes our vector of parameters \(\hat{x}\), minus the scalar \(f(\hat{x})\) multiplied by the inverse of the gradient vector:
Note: The \(f’(x_{n})\) in \(\frac{f(x_{n})}{f’(x_{n})}\) becomes \(\nabla f(\hat{x}_{n})^{-1}\) because we generalize the “reciprocal of the scalar, \(f(x_{n})\)” to the multivariate case, replacing it with the “inverse of the gradient, \(\nabla f(\hat{x}_{n})^{-1}\)”.
The Math: Maximizing Log-Likelihood with Newton’s Method
Recall that we want to maximize the log-likelihood, \(\ell(\theta)\) of our hypothesis function, \(h_{\theta}(x)\)
To maximize our function, we want to find the partial derivatives of \(\ell(\theta)\), and set them equal to 0, and solve for \(\theta_{1}\) and \(\theta_{2}\) to find the critical point of the partials. This critical point will be the max of our log-likelihood.
Note: Since the log-likelihood is strictly concave, we have one global max. This means that we only have 1 critical point, so our solution hashed out above is the only solution!
This should sound familiar. We are trying to find values for \(\theta_{1}\) and \(\theta_{2}\) that make the partial derivatives 0. We are finding the “roots” of the vector of partials (the gradient). We can use Newton’s Method to this! Recall the update step in Newton’s Method:
We can substitute \(f(\hat{x}_{n})\) with the gradient, \(\nabla \ell(\theta)\), leaving us with:
What about the \(?\) term above? Intuition tells us that we need to take the derivative of the gradient vector, just like we previously took the derivative of \(f(\hat{x}_{n})\).
Enter The Hessian.
The Math: The Hessian
Given our pre-requisite knowledge of Multivariate Calculus, we should know that to find the “second-order” partial derivatives of a function, we take the partial derivative of each first-order partial, with respect to each parameter. If we have \(n\) parameters, then we have \(n^{2}\) second-order partial derivatives.
Consequently, The Hessian is a square matrix of second-order partial derivatives of order \(n\ x\ n\).
In our case of 2 parameters, \((\theta_{1}, \theta_{2})\), our Hessian looks as follows:
The Math: Putting it all Together
By substituting The Hessian into the Newton’s Method update step, we are left with:
Note: We take the inverse of The Hessian, rather than taking its reciprocal because it is a matrix
For brevity’s sake, this post leaves out the actual derivation of the gradient and the hessian. Resources to understand the following derivations can be found at:
- Derivation of the Gradient of our Log-Likelihood, Andrew Ng’s lecture notes, pages 17-18.
- The derivation of the hessian is pretty straight forward, given Andrew Ng’s notes on the derivative of the sigmoid function, \(g’(z)\), once you’ve calculated the gradient.
The gradient of \(\ell(\theta)\) is:
While the hessian of \(\ell(\theta)\) is:
Where \(h_{\theta}(x) = \frac{1}{1 + e^{-z}}\) and \(z = \theta_{1}x + \theta_{2}\).
Implementing Newton’s Method
We start off by defining our hypothesis function, which is the sigmoid function.
def sigmoid(x, Θ_1, Θ_2):
z = (Θ_1*x + Θ_2).astype("float_")
return 1.0 / (1.0 + np.exp(-z))
Then we define \(\ell(\theta)\), our log-likelihood function:
def log_likelihood(x, y, Θ_1, Θ_2):
sigmoid_probs = sigmoid(x, Θ_1, Θ_2)
return np.sum(y * np.log(sigmoid_probs)
+ (1 - y) * np.log(1 - sigmoid_probs))
Finally, we implement the gradient and the hessian of our log-likelihood.
def gradient(x, y, Θ_1, Θ_2):
sigmoid_probs = sigmoid(x, Θ_1, Θ_2)
return np.array([[np.sum((y - sigmoid_probs) * x),
np.sum((y - sigmoid_probs) * 1)]])
def hessian(x, y, Θ_1, Θ_2):
sigmoid_probs = sigmoid(x, Θ_1, Θ_2)
d1 = np.sum((sigmoid_probs * (1 - sigmoid_probs)) * x * x)
d2 = np.sum((sigmoid_probs * (1 - sigmoid_probs)) * x * 1)
d3 = np.sum((sigmoid_probs * (1 - sigmoid_probs)) * 1 * 1)
H = np.array([[d1, d2],[d2, d3]])
return H
With all of our math implemented in these 4 functions, we can create the outer while loop and iterate using Newton’s Method until we converge on the maximum.
def newtons_method(x, y):
"""
:param x (np.array(float)): Vector of Boston House Values in dollars
:param y (np.array(boolean)): Vector of Bools indicting if house has > 2 bedrooms:
:returns: np.array of logreg's parameters after convergence, [Θ_1, Θ_2]
"""
# Initialize log_likelihood & parameters
Θ_1 = 15.1
Θ_2 = -.4 # The intercept term
Δl = np.Infinity
l = log_likelihood(x, y, Θ_1, Θ_2)
# Convergence Conditions
δ = .0000000001
max_iterations = 15
i = 0
while abs(Δl) > δ and i < max_iterations:
i += 1
g = gradient(x, y, Θ_1, Θ_2)
hess = hessian(x, y, Θ_1, Θ_2)
H_inv = np.linalg.inv(hess)
# @ is syntactic sugar for np.dot(H_inv, g.T)¹
Δ = H_inv @ g.T
ΔΘ_1 = Δ[0][0]
ΔΘ_2 = Δ[1][0]
# Perform our update step
Θ_1 += ΔΘ_1
Θ_2 += ΔΘ_2
# Update the log-likelihood at each iteration
l_new = log_likelihood(x, y, Θ_1, Θ_2)
Δl = l - l_new
l = l_new
return np.array([Θ_1, Θ_2])
Visualizing Newton’s Method
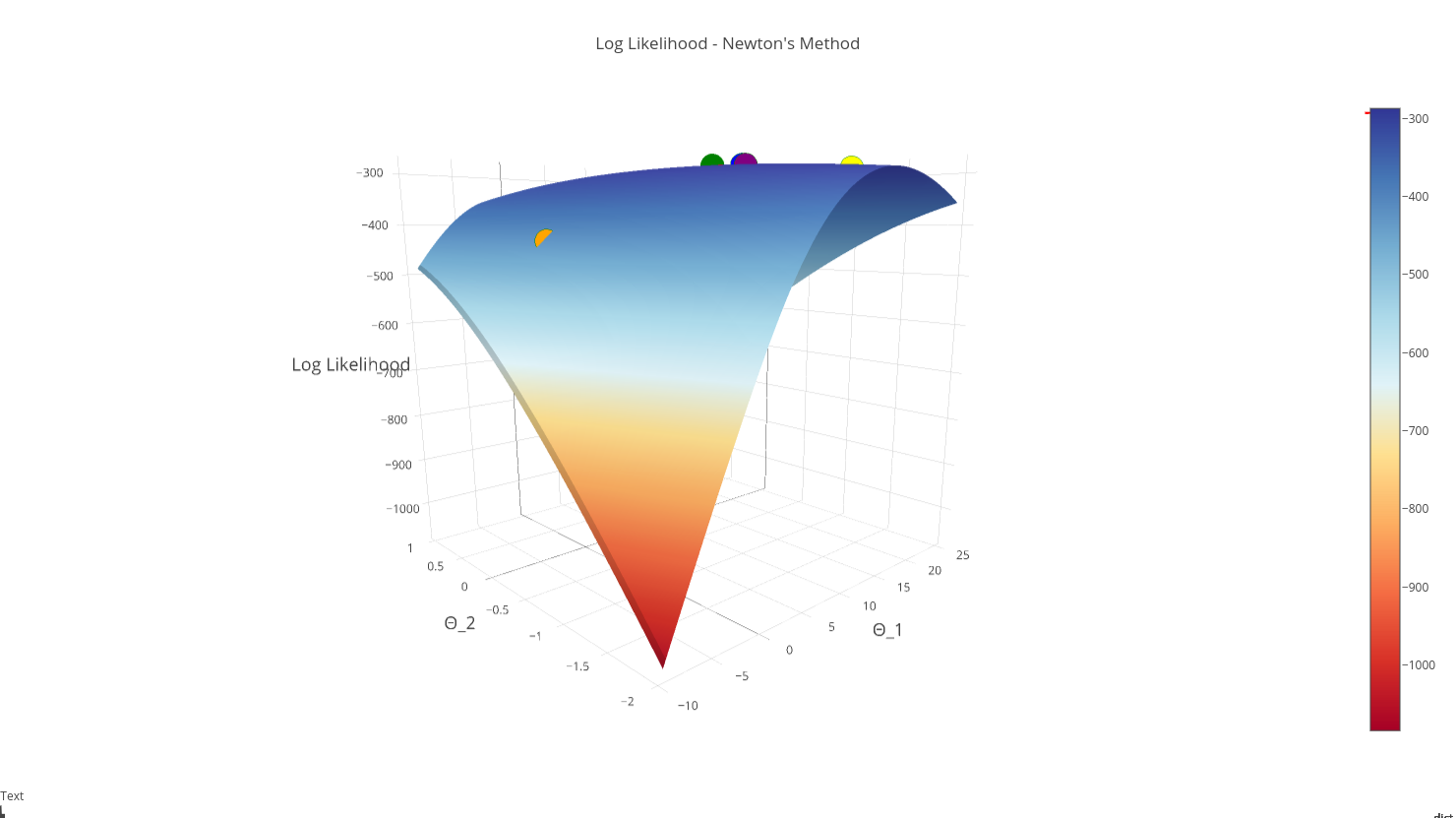
Let’s see what happens when we plot each iteration of Newton’s Method on our log-likelihood function’s surface:
Note: The first iteration is red, the second iteration is orange….final iteration is purple
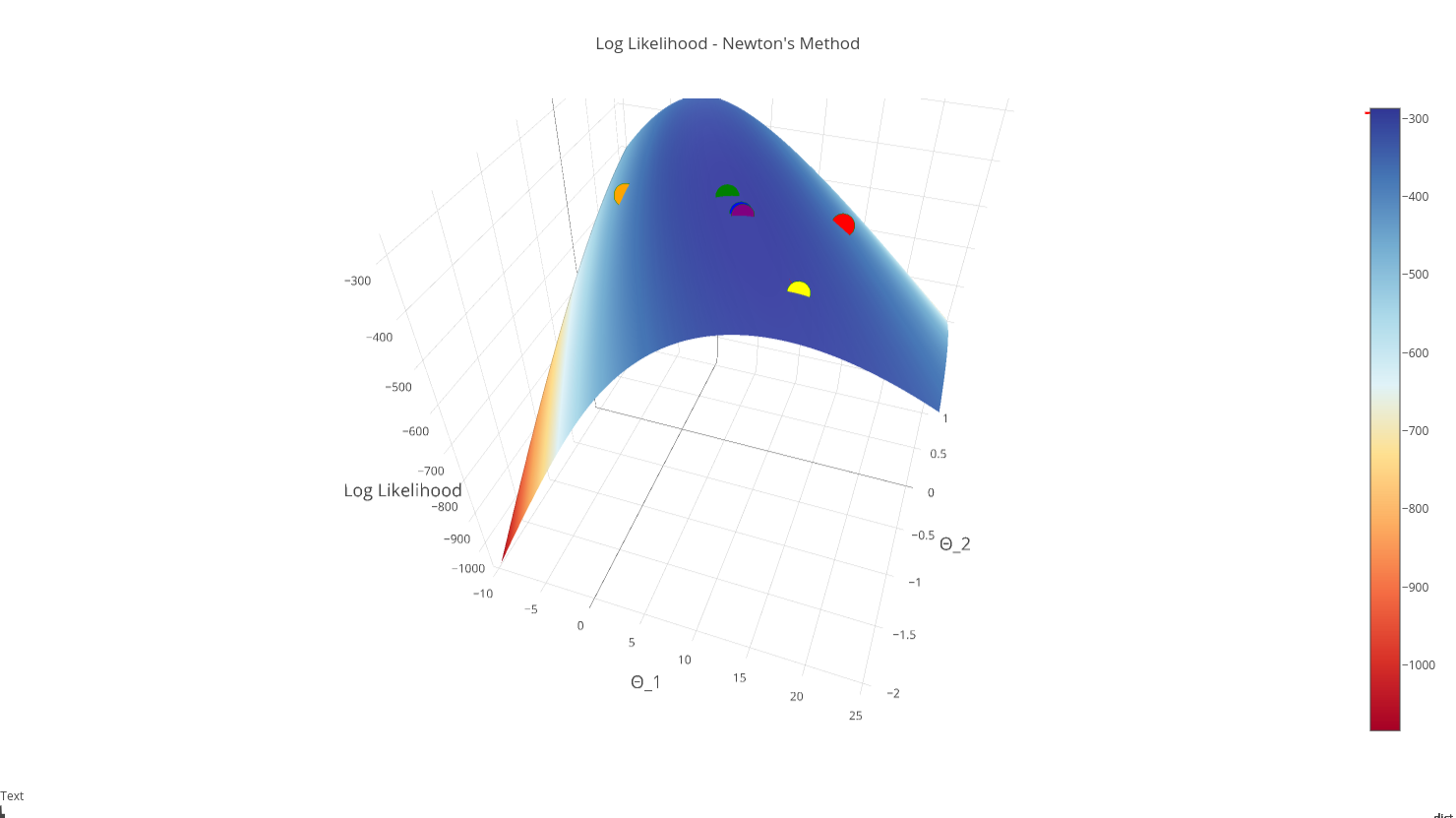
This graphic lends confirmation that our “purple” point is in fact the max, and that we have converged succesfully!
Visualizing our Solution
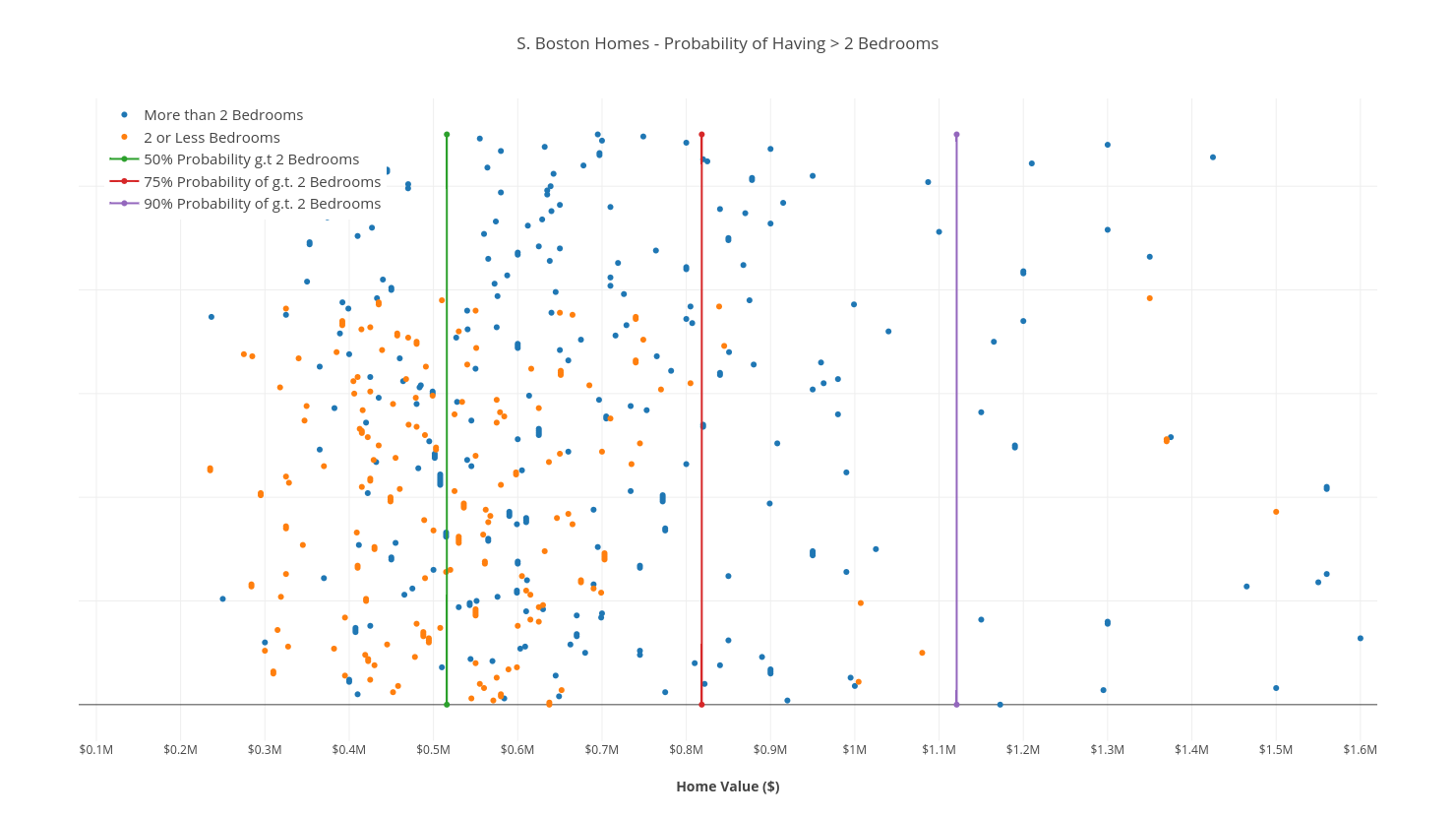
Normally, to visualize a 1-Dimensional dataset, you’d plot all of the points on a number-line, and place a boundary somewhere along the line. The problem here is that all of the data points get bunched together.
So instead, I’ve “stretched them out” along a y-axis, and labeled the points by color. We’ve also drawn 3 linear boundaries to separate the homes into percentiles – explained by the legend.
Conclusion
we have covered a number of new topics, including The Hessian, Log-likelihood and The Sigmoid Function. Combining these methods together, we’ve been able implement Newton’s Method to solve Logistic Regression.
While these concepts enforce a very concrete foundation to implement our solution, we still need to be wary of things that can cause Newton’s Method to diverge. These are out of scope here, but you can read more on divergence here!